
TL;DR: AI tools supporting revenue-related work are widely adopted, but true AI-driven revenue recognition calculation (the deterministic engine that produces auditable journal entries) does not yet exist in production-ready form. What’s available today stops well short of the calculation layer.
Seventy-two percent of finance teams are using AI for revenue-related work. Almost none are using it for actual revenue recognition.
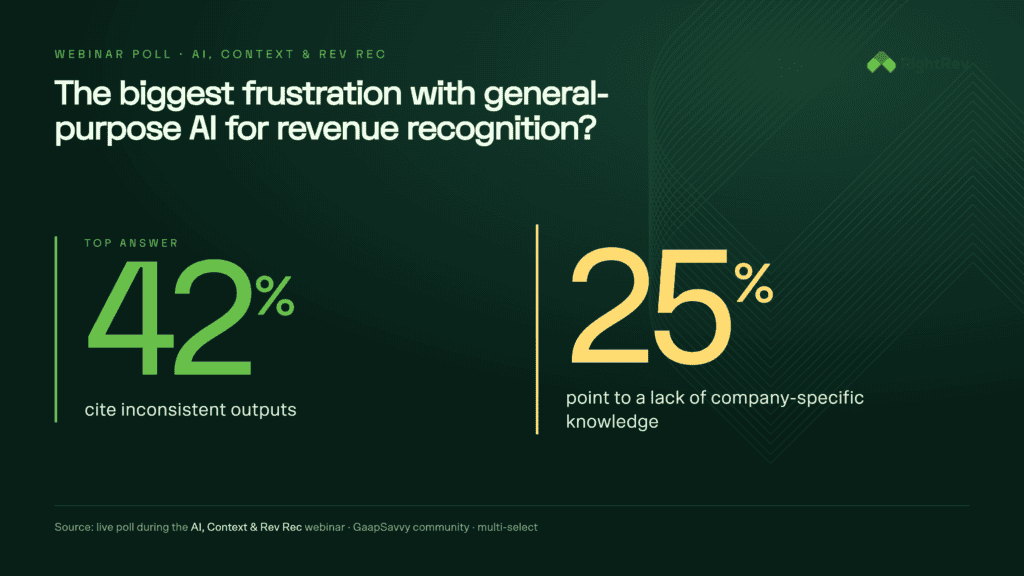
According to a poll we ran during our webinar with Gaapsavvy, the disconnect shows up in two numbers: 42% cite inconsistent outputs as their primary frustration, and 25% point to lack of company-specific knowledge. These aren’t complaints about model performance. They’re symptoms of a deeper architectural problem: AI tools are being asked to produce deterministic accounting outputs from probabilistic reasoning, without access to the structured context layer that makes those outputs defensible.
Better prompts alone won’t close the gap between adoption and trust. Context engineering will, and that work can only be done by accountants who understand the domain. The real question is whether the context layer underneath has been built to accounting standards.
This article examines what that context layer requires, why it can’t be automated away, and why the accountant’s role in building it is expanding, not shrinking.
Why Inconsistency Is the Symptom, Not the Disease
When a finance leader asks, “Why did revenue decrease for this customer?” a generic AI model returns a plausible answer: contract churn, pricing changes, usage decline. A context-aware system returns a precise answer: a contract modification on March 15 reduced the transaction price by $120K, which triggered a cumulative catch-up adjustment under ASC 606-10-25-13, reducing recognized revenue by $80K in the current period. The model is the same. The accounting context behind it is not.
Probabilistic models generate outputs based on pattern recognition across training data. Revenue recognition requires deterministic logic based on contract terms, accounting policies, and transaction history. Without a structured foundation that encodes those rules, the model defaults to approximation. That works for summarization. It fails for compliance.
The real problem surfaces during reconciliation. A controller can’t trace an AI-generated revenue figure back to a specific performance obligation, allocation method, or policy election if the output disappeared into a chat window. The model may be statistically accurate across thousands of scenarios, but accounting doesn’t operate on statistical accuracy. It operates on traceability, repeatability, and auditability. Inconsistency is what happens when probabilistic reasoning meets deterministic requirements without the right infrastructure underneath.
The Context Layer Already Exists, In Your Head
The context layer already exists. Finance teams use it every month to close the books. The problem is that knowledge has never been formalized in a way AI can access, validate, and execute against.
The Five Context Layers Finance Teams Already Maintain
- Business context: Who are your customers? What legal entities do you operate under? What products do you sell, in what regions, under what contract types? CRM data captures relationships. This captures how revenue flows. Without it, AI can’t distinguish between a customer account and a GL account. It can’t tell whether “Acme Industrial” refers to a parent entity or a subsidiary. It doesn’t know that your EMEA contracts follow different performance obligation structures than your US contracts.
- Accounting policy context: What’s your ASC 606 policy? How do you determine SSP? How do you treat variable consideration? What’s your FX policy, separate gain/loss account or direct to revenue? These are judgment calls. They require documentation and consistency to hold up. AI doesn’t know whether you allocate retrospectively or prospectively after a contract modification. It doesn’t know your materiality thresholds. It doesn’t know that you changed your SSP methodology in Q2 of last year and why that matters for comparability.
- Transaction context: How are orders structured? What does an invoice look like? Where does usage data come from? How do amendments and renewals flow through the system? This is the data model that connects billing to revenue recognition. Without it, AI can’t reconcile a thousand transactions in Salesforce billing against what actually made it into your revenue system. It can’t tell whether a credit memo represents a refund, a contract modification, or a pricing correction. It doesn’t know that your usage data arrives in three different formats depending on which product line generated it.
- Historical context: What happened in the prior period? What modifications were made? What precedent decisions exist for similar contracts? This is institutional memory, the knowledge that prevents inconsistency across periods. AI doesn’t know that you treated a similar contract modification prospectively last quarter. It doesn’t know that the customer’s prior contract included professional services that were accounted for separately. It doesn’t know that this is the third amendment to a multi-year deal and how that affects cumulative catch-up adjustments.
- Calculation context: How does allocation logic work? Are waterfall schedules daily or equally distributed? What rounding policies apply? How are FX calculations performed? These are the technical rules that produce the numbers. You would only know about those annoying rounding issues if you’ve gotten burned by them many times. AI doesn’t know that your system rounds at the line level before summing, which creates reconciliation gaps. It doesn’t know that you calculate FX at the invoice date, not the recognition date. It doesn’t know that your allocation logic treats zero-dollar line items differently than your billing system does.
Why This Knowledge Has Never Been Formalized
Finance teams carry this context in their heads, in annotated spreadsheets, in email threads, in tribal knowledge. It’s never been formalized because systems didn’t need it, humans were the execution layer. You would take these downloaded spreadsheets. You’d have like “account account” or “date date” or “name name,” and then above it you’d type “this name in this context means this” or “this name came from Salesforce.” You’d have to remember it and share this spreadsheet and say “this is what this table field means.” But the system never got that information.
The shift to AI exposes the gap: AI can’t access informal knowledge. It can’t read your annotated headers. It can’t parse the email thread where you explained why this customer’s contract is treated differently. It can’t sit in on the month-end close meeting where you walk through the edge cases. Context engineering is the work of making implicit knowledge explicit, encoding what you already know in a way that AI can execute against consistently.
Concrete Example: The “Why Did Revenue Decrease?” Question
Without context: AI gives a generic answer: revenue may have declined due to churn, discounts, or usage changes. That’s statistically likely across thousands of scenarios, but it’s operationally useless. You can’t trace it back to a specific contract. You can’t validate it against your policy. You can’t explain it to your CFO or your auditors.
With context: AI can specify: revenue decreased by $120K because the customer contract was modified on March 15, reducing the quantity by 30%, which triggered a prospective allocation change under your ASC 606 policy. The modification removed one performance obligation, which shifted $80K of previously recognized revenue into future periods. The remaining $40K represents the cumulative catch-up adjustment required under ASC 606-10-25-13. Here’s the contract version history. Here’s the allocation waterfall. Here’s the journal entry.
The difference is whether the model has access to the full revenue context. This is the gap between summarization and execution. Summarization tolerates approximation. Execution requires precision. Revenue recognition is an execution problem, not a summarization problem.
For more on how revenue recognition principles under GAAP require deterministic execution, not probabilistic inference, see our breakdown of the compliance requirements that make context engineering non-negotiable.
What Audit-Ready AI Actually Requires
When 42% of finance teams report inconsistent AI outputs and 25% cite lack of company-specific knowledge, the cost goes beyond operational friction. Audit exposure, revenue restatement risk, compliance failure, the list goes on. The gap between AI adoption and AI trust in revenue recognition comes down to architecture, not training. Most finance teams discover this after implementation, not before.
Meeting those four non-negotiables is what separates audit-ready AI from general-purpose AI applied to revenue recognition.
- Determinism: The same inputs must produce the same outputs every time. This is a compliance requirement. Auditors need to trace every decision, validate every calculation, and confirm that the same scenario would produce the same result if re-run. Most AI systems are designed to generate likely answers, not deterministic outputs. You cannot have probabilistic accounting. The same inputs under the same policy with the same configuration must produce the same output every single time. That sounds obvious, but it’s a core challenge with applying general-purpose AI to finance. The real challenge is building a deterministic layer underneath AI that enforces rules-based execution.
- Context-aware: AI cannot operate on fragmented data. Revenue recognition is a chain of connected decisions across contract terms, products, pricing, billing, SSP, allocations, modifications, FX, journal entries. A model that only sees a contract clause may miss how the clause impacts allocation. A model that only sees an invoice has no idea how revenue is being recognized. Audit-ready AI requires the full revenue context, across every data source. This is what separates purpose-built revenue recognition AI from general-purpose AI applied to revenue recognition. You are already doing this context in your head and trying to do all this manually. You are already doing this context work in your head and translating it manually into spreadsheets and systems. The role of AI today is to help surface, analyze, and interpret that context, not to execute the calculations themselves. The calculation engine remains deterministic and rules-based; AI operates above it, as an analytical and investigative layer, not the arithmetic core.
- Governed: Every decision needs an evidence trail. If AI recommends a treatment, you need to know why it’s recommending it. If it flags an anomaly, you need to know what rule or pattern triggered it. If there’s a variance, you need to trace and explain why it’s happening. The outputs cannot disappear into a chat window, they must be preserved, auditable, and explainable. This entire conversation is preserved and will be available for you and the auditors any time. This is not a black-box AI. We expose everything back to the users and auditors, what it’s writing.
- Human in the loop: AI recommends, accountants decide. Audit-ready AI does not mean removing the accountant from the process, it means changing the accountant’s role. Today, too much of the revenue team’s time is spent gathering data, tracking transactions, building spreadsheets. AI should isolate information, detect anomalies, and surface issues, but it shouldn’t make policy decisions. The accountant remains the decision-maker, especially on policy and judgment calls. The AI needs to make sure it can recommend but it cannot make a decision, especially on the policy side.
The question from a recent webinar about stale context layers gets at a real governance issue: if the context layer becomes outdated, does the AI start producing wrong answers? The answer is yes, which is why you do not update the context layer from the chatbot. It’s super risky. You have to work with whoever has built the context layer to give the context and build it. If you’re going to allow the chatbot to drive it, it’ll become a disaster. It’s a control issue. Context layer updates are a governance process, not an automation feature.
The reconciliation gap question from the webinar, how much of AI revenue recognition is actually about clean transactional data feeds versus the AI rules engine itself, points to the same architectural reality. Most revenue recognition pain starts with reconciliation gaps between billing, payments, and the GL. AI doesn’t solve data quality problems, it exposes them. This is where agent-to-agent workflows become critical. If a RightRev agent can talk to a Salesforce agent, it can automatically connect to Salesforce and figure out: there are a thousand transactions in Salesforce billing, and are all thousand transactions available in RightRev? That’s how we are going to completely eliminate that reconciliation and have the agent do the automatic reconciliation.
For more on how revenue recognition principles under GAAP require deterministic execution, not probabilistic inference, see our breakdown of the compliance requirements that make context engineering non-negotiable.
The Accountant’s Role Is Shifting, Not Disappearing
The accountant’s role in the AI era isn’t to process transactions; it’s to direct the outcomes that matter.
AI doesn’t replace accounting judgment. It scales it. The accountant defines the rules, the policies, the edge cases, the exceptions. AI executes those rules consistently across thousands of transactions. The shift is from “processing transactions manually” to “defining how transactions should be processed.” This is a higher-value role, not a lower-value role. We were literally doing this anyways, it was just disorganized and verbal or on random spreadsheets.
Now there’s a way to store those semantic meanings, connect those relationships, and layer in the new stuff you’re learning.
The heavy lifting of context engineering, encoding business rules, accounting policies, transaction logic, and calculation constraints into a structured foundation, is work that purpose-built platforms like RightRev handle. Finance teams don’t need to build the context layer from scratch or maintain it like a second system. That infrastructure already exists.
What this means for finance teams: less time on data gathering, spreadsheet building, manual journal entries. More time on policy definition, use case design, anomaly investigation, audit preparation. The skill set shifts from technical accounting execution to technical accounting architecture. Finance teams become process and systems thinkers, not just transaction processors.
If your revenue recognition process involves manual workarounds, contract modifications, usage-based pricing, multi-element arrangements, or variable consideration, and you’re experiencing inconsistent AI outputs or a lack of company-specific context, the right move is purpose-built software with a context layer built to accounting standards.
Request a demo to see how RightRev’s context layer turns AI from a summarization tool into an audit-ready accounting engine.
How Revenue Recognition Software Fits Into the Stack
A revenue recognition subledger sit between your billing platform and your general ledger. They don’t replace either. They reconcile the gap between how you invoice customers and how you recognize revenue under ASC 606. That gap, between billing events and revenue schedules, is where compliance risk lives.
Your ERP wasn’t designed to handle contract-level allocation logic, multi-element arrangements, or usage-based revenue models at scale. It’s built to record journal entries, not to architect them from contract terms. Your billing system knows when to invoice. It doesn’t know when to recognize. That’s the structural problem revenue recognition software solves.
A purpose-built revenue subledger maintains the full audit trail from contract to journal entry. It handles SSP allocation, waterfall schedules, modification logic, and FX treatment, then posts summarized entries to the GL. The subledger becomes the system of record for revenue, while the ERP remains the system of record for the financial statements. This is how you maintain control when revenue complexity exceeds what the ERP architecture was designed to handle.
The context layer that makes AI useful in revenue recognition, the five layers of business, policy, transaction, historical, and calculation context, lives in the revenue subledger, not in the billing system or the ERP. That’s why AI for revenue recognition can’t be bolted onto upstream tools. The context isn’t there. For more on how revenue recognition principles under GAAP require deterministic execution at the contract level, see our breakdown of the compliance requirements that make subledger architecture non-negotiable.
If your revenue model includes usage-based pricing, multi-element arrangements, or contract modifications, and you’re trying to manage revenue recognition in spreadsheets or ERP modules, request a demo to see how a purpose-built subledger changes the control environment. For finance leaders evaluating how AI fits into the revenue close process, our guide to revenue recognition in the AI era walks through the architectural requirements that determine whether AI adds value or introduces risk.
Key Takeaways
If your revenue model includes usage-based pricing, multi-element arrangements, contract modifications, or variable consideration, and you’re experiencing inconsistent AI outputs or lack of company-specific context, the solution isn’t a better model, it’s building the context layer that makes AI outputs audit-ready.
AI adoption in revenue recognition is high (94%), but trust in core accounting execution is low, because probabilistic models can’t produce deterministic outputs without a structured context layer underneath.
The context layer isn’t new work, it’s encoding the knowledge finance teams already use to close the books (business rules, accounting policies, transaction history, calculation logic, controls).
Audit-ready AI requires four non-negotiables: deterministic execution, context-aware processing, governed outputs with audit trails, and human-in-the-loop decision-making.
The accountant’s role is shifting from transaction processor to context engineer, the person who defines what AI needs to know to produce audit-ready outputs.
Frequently Asked Questions
What is an automated revenue management system
An automated revenue management system is a platform that ingests contract and billing data, applies revenue recognition logic based on accounting standards, maintains a revenue sub-ledger, and produces the journal entries and reports needed for financial close. It replaces manual spreadsheet-based processes and reduces the risk of errors at scale.
How does revenue recognition automation reduce close cycle time?
Automation eliminates the manual steps of pulling contract data, building recognition schedules, manually calculating allocations, and reconciling sub-ledgers. By processing contracts in real time and maintaining a continuously updated revenue position, automated systems can compress close from days to hours, giving finance teams more time for analysis and review.
What are the most common SaaS accounting compliance challenges under ASC 606?
Common challenges include correctly identifying and separating performance obligations in bundled deals, determining and documenting standalone selling prices, handling contract modifications from upgrades and downgrades, accounting for variable consideration from usage tiers, and managing the volume of contracts at scale without automation.


